
Optimizing LLM Prompt Engineering with Farsight OPRO SDK
Jan 31, 2024
Working with large language models (LLMs) often involves endless tinkering and tweaking of system prompts, with the hope that the model will eventually respond as intended. Recognizing this bottleneck, Google DeepMind introduced an innovative approach, Optimization by PROmpting (OPRO), where LLMs autonomously refine and optimize their system prompts. In this article, we research the extensibility of the OPRO method and introduce the OPRO SDK — a user-friendly tool that streamlines this process, saving valuable time and reducing frustration.
Overview of the OPRO Method
OPRO uses LLMs to generate and iteratively improve system prompts. Initiating this process requires a dataset of around 50 input-target pairs. Starting from a basic prompt such as “Let’s solve the problem,” OPRO generates model responses for the dataset, which are then scored against the desired targets. The system continuously improves by generating 8 new prompts based on the performance of the top 20 prompts, testing each new batch against the training data, and refining the process through successive iterations. In the generation process, the temperature is set to 1, signifying that the model’s output becomes more random and varied. As a result, the iterative improvement process explores a wide range of prompting possibilities and is capable of learning a linguistic trajectory based on previous prompts and their corresponding scores in each iteration, ultimately often reaching convergence.
Experimental Setup
While OPRO tested the models text-bison and PaLM 2-L, our experimentation with OPRO involved utilizing the GPT-3.5-turbo model as both the system prompt generator and outputs generator, testing the framework’s adaptability to more widely used and accessible models. We used keyword matching to evaluate outputs with targets. Despite the standard OPRO methodology encompassing around 200 iterations, we investigated the efficacy of reducing this number to accommodate user convenience and cost-effectiveness. The findings were promising, indicating significant improvements in training accuracy after just 40 iterations, suggesting a viable reduction in both time and expense for users.
Our Results
In this section, we present the results of our experiments conducted on eight Big Bench Hard tasks, each consisting of 250 input-target pairs, with a training-to-testing ratio of 20:80. The graphed results illustrate a positive training trajectory even with the reduced iteration count from 200 to 40, validating OPRO extensibility to GPT-3.5-Turbo and also its capability to enhance model performance significantly within a fraction of the standard iteration timeframe.

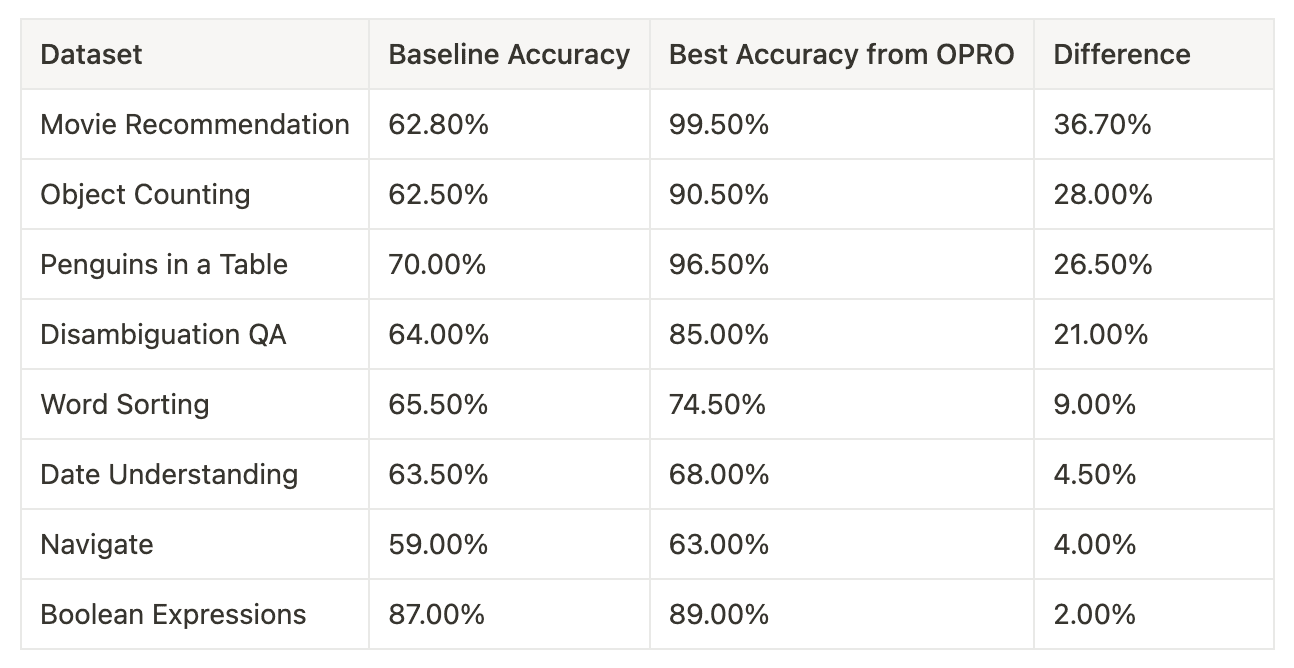
Our training findings demonstrate a consistently positive training trajectory with GPT-3.5-Turbo. Across various BBH tasks we examined, we found notable accuracy improvements, albeit to varying degrees. Tasks such as Navigate and Boolean Expressions exhibited relatively modest gains in test accuracy. In contrast, tasks like Movie Recommendations and Object Counting displayed remarkable flexibility in accuracy when prompted, with increases of 36.70% and 28.00%, respectively. These results underscore the model’s sensitivity to different forms of prompting for specific tasks.
Comparison to OPRO
We compared the outcomes of our OPRO experiments involving GPT-3.5-Turbo across 40 iterations against the initial tests conducted in the paper utilizing text-bison and PaLM 2-L with 200 iterations. Here are the results and key insights garnered from this comparison.
General Comparison
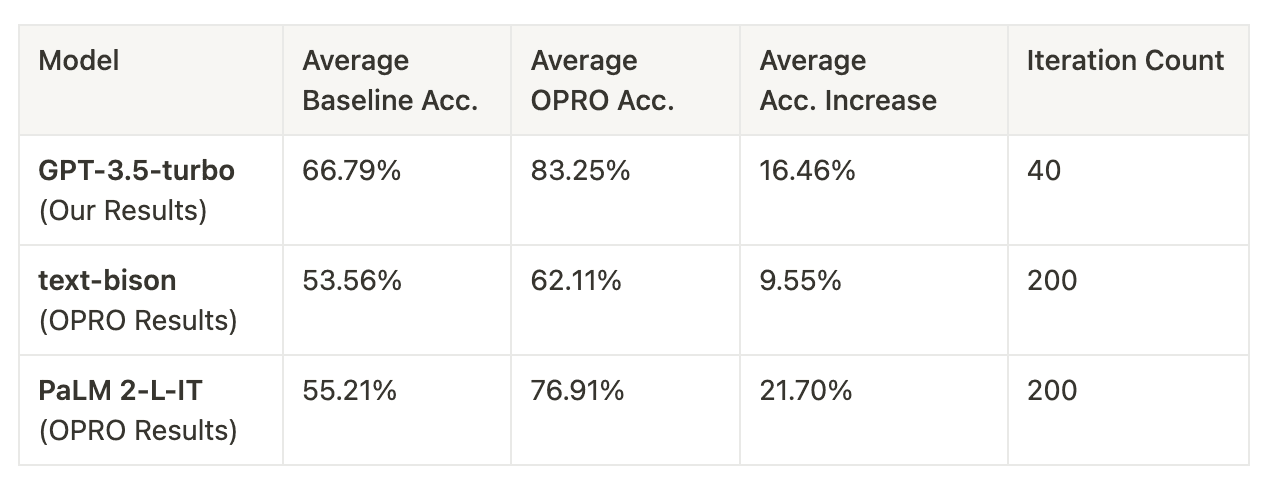
Shortening OPRO iterations still results in an overall accuracy improvement. The training accuracy trajectory depicted in the plotted figures, along with a remarkable 16.46% average increase in test accuracy, validates that even when reducing the iteration count from 200 to 40, substantial accuracy improvements are achievable. This outcome could potentially suggest that GPT-3.5 Turbo is perhaps a more adept learner when it comes to identifying the optimal linguistic trajectory for optimizing a prompt.
OPRO approach is extensible to GPT-3.5-Turbo. the adaptability of the OPRO approach to GPT-3.5-Turbo is demonstrated by the training trajectory observed in the plotted figures, mirroring the outcomes presented in the OPRO paper. Notably, text-bison and PaLM 2-L displayed average accuracy increases of 9.55% and 21.70%, respectively. GPT-3.5-Turbo’s average accuracy increase falls within these margins, affirming the broad applicability of the OPRO approach to various LLM models.
High baseline accuracy can still lead to a substantial accuracy increase with OPRO. Even when starting with a notably higher baseline accuracy of 66.79% compared to text-bison and PaLM 2-L, GPT-3.5-Turbo demonstrated a substantial accuracy increase of 16.46%. This underscores the efficacy of OPRO prompt optimization, even when applied to models with already high baseline accuracy levels.
Task Level Comparison
The OPRO paper’s comparison of models with our GPT-3.5-Turbo results did not yield a consistent pattern regarding which tasks experienced substantial accuracy improvements and which saw minimal gains. Two illustrative examples highlight this lack of clear trends. While some tasks consistently performed better with one model over another, there was no discernible pattern to indicate which tasks favored a specific model.
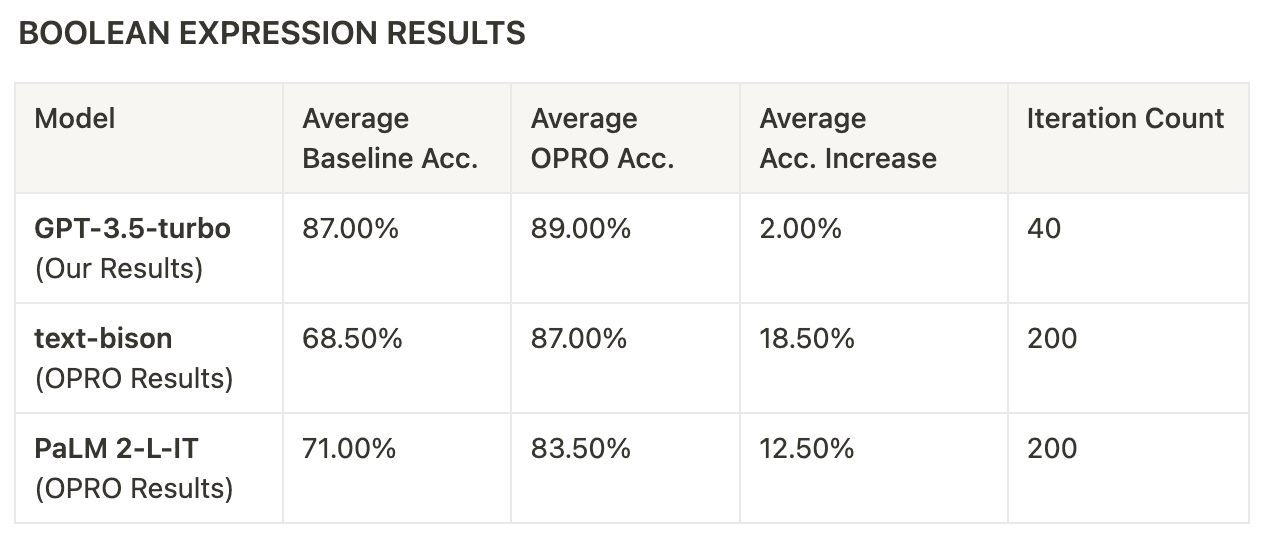
Discrepancies in accuracy improvements may be attributed to reaching an upper limit of achievable accuracy from prompting alone. For instance, Boolean Expressions exhibited substantial increases in accuracy with text-bison and PaLM 2-L, registering improvements of 18.50% and 12.50%, respectively, while GPT-3.5-Turbo only saw a modest 2.0% increase. However, it’s worth noting that the highest accuracy text-bison and PaLM 2-L achieved was 87.0%, which coincided with the baseline of GPT-3.5-Turbo. This suggests that the relatively small improvements observed with GPT-3.5-Turbo may indicate that the model had already reached the upper limit of achievable accuracy through prompting alone for this specific task.
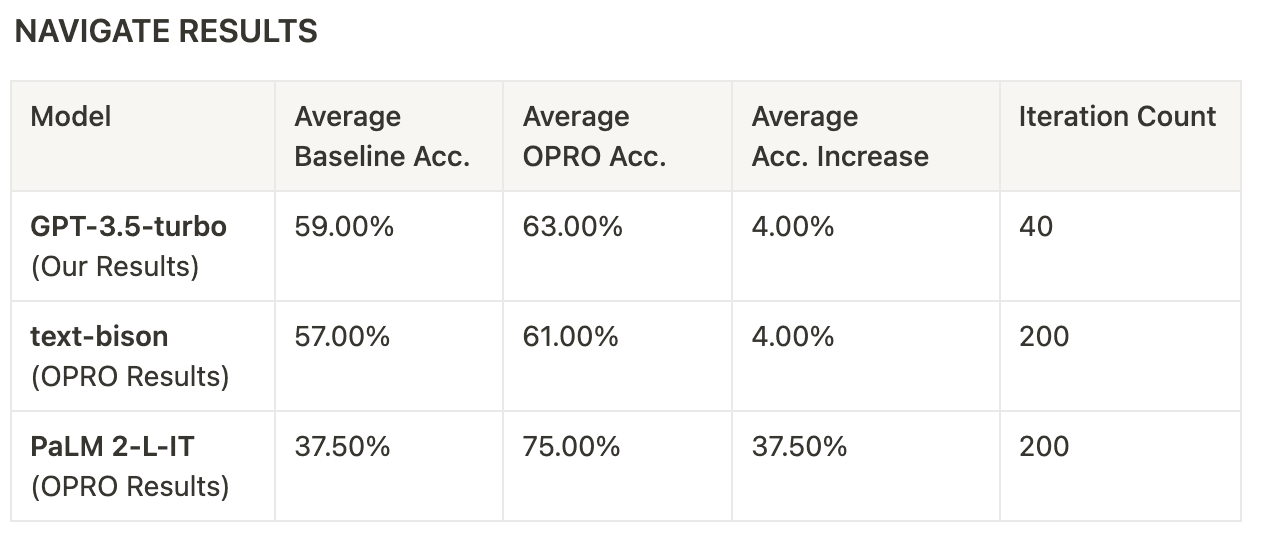
Even when starting from a lower baseline, the choice of the right prompt can lead one model to outperform others significantly. In the case of the Navigate task, GPT-3.5-Turbo and text-bison boasted notably higher baselines of 59.0% and 57.0%, respectively, compared to PaLM 2-L’s 37.50%. Nevertheless, through the OPRO approach and the identification of the optimal prompt, PaLM 2-L outperformed the other models by approximately 10.0% in final accuracy. This suggests that baseline accuracies do not always serve as reliable predictors of one model outperforming another when the right prompt is employed.
Conclusion: Enhancing LLM Efficiency with OPRO and GPT-3.5-turbo
OPRO’s prompt optimization method and the capabilities of the GPT-3.5-turbo model have proven to be highly effective, significantly improving accuracy on challenging LLM tasks with a reduced number of iterations. This advancement not only accelerates the development process but also opens up new possibilities for prompt engineering efficiency. For those interested in leveraging this powerful tool, we encourage you to explore our SDK documentation and GitHub repository for further details.
Optimizing LLM Prompt Engineering with Farsight OPRO SDK
Jan 31, 2024
Working with large language models (LLMs) often involves endless tinkering and tweaking of system prompts, with the hope that the model will eventually respond as intended. Recognizing this bottleneck, Google DeepMind introduced an innovative approach, Optimization by PROmpting (OPRO), where LLMs autonomously refine and optimize their system prompts. In this article, we research the extensibility of the OPRO method and introduce the OPRO SDK — a user-friendly tool that streamlines this process, saving valuable time and reducing frustration.
Overview of the OPRO Method
OPRO uses LLMs to generate and iteratively improve system prompts. Initiating this process requires a dataset of around 50 input-target pairs. Starting from a basic prompt such as “Let’s solve the problem,” OPRO generates model responses for the dataset, which are then scored against the desired targets. The system continuously improves by generating 8 new prompts based on the performance of the top 20 prompts, testing each new batch against the training data, and refining the process through successive iterations. In the generation process, the temperature is set to 1, signifying that the model’s output becomes more random and varied. As a result, the iterative improvement process explores a wide range of prompting possibilities and is capable of learning a linguistic trajectory based on previous prompts and their corresponding scores in each iteration, ultimately often reaching convergence.
Experimental Setup
While OPRO tested the models text-bison and PaLM 2-L, our experimentation with OPRO involved utilizing the GPT-3.5-turbo model as both the system prompt generator and outputs generator, testing the framework’s adaptability to more widely used and accessible models. We used keyword matching to evaluate outputs with targets. Despite the standard OPRO methodology encompassing around 200 iterations, we investigated the efficacy of reducing this number to accommodate user convenience and cost-effectiveness. The findings were promising, indicating significant improvements in training accuracy after just 40 iterations, suggesting a viable reduction in both time and expense for users.
Our Results
In this section, we present the results of our experiments conducted on eight Big Bench Hard tasks, each consisting of 250 input-target pairs, with a training-to-testing ratio of 20:80. The graphed results illustrate a positive training trajectory even with the reduced iteration count from 200 to 40, validating OPRO extensibility to GPT-3.5-Turbo and also its capability to enhance model performance significantly within a fraction of the standard iteration timeframe.
Our training findings demonstrate a consistently positive training trajectory with GPT-3.5-Turbo. Across various BBH tasks we examined, we found notable accuracy improvements, albeit to varying degrees. Tasks such as Navigate and Boolean Expressions exhibited relatively modest gains in test accuracy. In contrast, tasks like Movie Recommendations and Object Counting displayed remarkable flexibility in accuracy when prompted, with increases of 36.70% and 28.00%, respectively. These results underscore the model’s sensitivity to different forms of prompting for specific tasks.
Comparison to OPRO
We compared the outcomes of our OPRO experiments involving GPT-3.5-Turbo across 40 iterations against the initial tests conducted in the paper utilizing text-bison and PaLM 2-L with 200 iterations. Here are the results and key insights garnered from this comparison.
General Comparison
Shortening OPRO iterations still results in an overall accuracy improvement. The training accuracy trajectory depicted in the plotted figures, along with a remarkable 16.46% average increase in test accuracy, validates that even when reducing the iteration count from 200 to 40, substantial accuracy improvements are achievable. This outcome could potentially suggest that GPT-3.5 Turbo is perhaps a more adept learner when it comes to identifying the optimal linguistic trajectory for optimizing a prompt.
OPRO approach is extensible to GPT-3.5-Turbo. the adaptability of the OPRO approach to GPT-3.5-Turbo is demonstrated by the training trajectory observed in the plotted figures, mirroring the outcomes presented in the OPRO paper. Notably, text-bison and PaLM 2-L displayed average accuracy increases of 9.55% and 21.70%, respectively. GPT-3.5-Turbo’s average accuracy increase falls within these margins, affirming the broad applicability of the OPRO approach to various LLM models.
High baseline accuracy can still lead to a substantial accuracy increase with OPRO. Even when starting with a notably higher baseline accuracy of 66.79% compared to text-bison and PaLM 2-L, GPT-3.5-Turbo demonstrated a substantial accuracy increase of 16.46%. This underscores the efficacy of OPRO prompt optimization, even when applied to models with already high baseline accuracy levels.
Task Level Comparison
The OPRO paper’s comparison of models with our GPT-3.5-Turbo results did not yield a consistent pattern regarding which tasks experienced substantial accuracy improvements and which saw minimal gains. Two illustrative examples highlight this lack of clear trends. While some tasks consistently performed better with one model over another, there was no discernible pattern to indicate which tasks favored a specific model.
Discrepancies in accuracy improvements may be attributed to reaching an upper limit of achievable accuracy from prompting alone. For instance, Boolean Expressions exhibited substantial increases in accuracy with text-bison and PaLM 2-L, registering improvements of 18.50% and 12.50%, respectively, while GPT-3.5-Turbo only saw a modest 2.0% increase. However, it’s worth noting that the highest accuracy text-bison and PaLM 2-L achieved was 87.0%, which coincided with the baseline of GPT-3.5-Turbo. This suggests that the relatively small improvements observed with GPT-3.5-Turbo may indicate that the model had already reached the upper limit of achievable accuracy through prompting alone for this specific task.
Even when starting from a lower baseline, the choice of the right prompt can lead one model to outperform others significantly. In the case of the Navigate task, GPT-3.5-Turbo and text-bison boasted notably higher baselines of 59.0% and 57.0%, respectively, compared to PaLM 2-L’s 37.50%. Nevertheless, through the OPRO approach and the identification of the optimal prompt, PaLM 2-L outperformed the other models by approximately 10.0% in final accuracy. This suggests that baseline accuracies do not always serve as reliable predictors of one model outperforming another when the right prompt is employed.
Conclusion: Enhancing LLM Efficiency with OPRO and GPT-3.5-turbo
OPRO’s prompt optimization method and the capabilities of the GPT-3.5-turbo model have proven to be highly effective, significantly improving accuracy on challenging LLM tasks with a reduced number of iterations. This advancement not only accelerates the development process but also opens up new possibilities for prompt engineering efficiency. For those interested in leveraging this powerful tool, we encourage you to explore our SDK documentation and GitHub repository for further details.

© 2024 Farsight AI, Inc.
All rights reserved.
Corporate HQ:
One Kendall Square, Suite B2102, Cambridge, MA 02139
NY Office:
2 Park Ave (Floor 20), New York, NY 10016
© 2024 Farsight AI, Inc.
All rights reserved.
Corporate HQ:
One Kendall Square, Suite B2102, Cambridge, MA 02139
NY Office:
2 Park Ave (Floor 20), New York, NY 10016
© 2024 Farsight AI, Inc.
All rights reserved.
Corporate HQ:
One Kendall Square, Suite B2102, Cambridge, MA 02139
NY Office:
2 Park Ave (Floor 20), New York, NY 10016