
An LLM Benchmark for Financial Document Question Answering
Jan 24, 2024
Generative Artificial Intelligence (GenAI) has unlocked a multitude of new applications across numerous sectors, including financial services. As part of our continuous efforts to explore the potentials and limitations of AI, we at Farsight conducted an experiment to evaluate the capabilities of various popular Large Language Models (LLMs) in the context of financial document analysis, particularly 10-Ks and 10-Qs — a quarterly report filed by public companies regarding their financials.
Our results include three major findings:
Out-of-the-box LLMs have far from satisfactory performance: Even when provided the necessary context to answer a financial question, out-of-the-box LLMs spectacularly fail to meet the production standards required in the financial sector, with most models incorrectly answering ~40% of questions.
Rising strength of open-source: While GPT-4 remains the top model, GPT-3.5’s performance has been eclipsed by the open-source SOLAR-10.7b model.
Calculation tasks remain a major pitfall: 7 of the 8 models evaluated failed on over half of calculation-related tasks they were presented with. GPT-4 led all models with only 57% accuracy on such tasks.
We constructed our benchmark from a 10-K dataset hosted on Hugging Face. Based on contexts drawn from this dataset, we generated questions covering 3 categories of interest (calculations, financial domain knowledge, and regulatory knowledge) using GPT-4-Turbo. We then ask a variety of LLMs to answer these questions given the relevant context, and finally, evaluate each model’s responses using GPT-4-Turbo to determine correctness based on the information provided in the associated context. Unlike existing financial benchmarks, we emphasized design decisions that enable automation and extensibility throughout this process in order to facilitate repurposing this work for benchmarking LLMs in other domains, as well as other specific financial services use cases.
Our main objectives of this benchmark were to:
Understand the outright performance of current-generation LLMs on financial text, given golden context. We explicitly include golden context so performance gaps are not confounded with retrieval errors.
Compare performance between LLMs (open-source and closed-source) across three types of questions (calculations, financial domain knowledge and regulatory knowledge).
Present an efficient and automated method to evaluate various foundation models on domain-specific tasks (our process is 100x more efficient than current practices for evaluation).
Note: Golden context refers to a small snippet of content (2–3 paragraphs) that contains a substantial portion of the information needed to correctly answer a question.
We provide our results and analysis first, then elaborate further on our dataset creation and evaluation process.
Results + Analysis
In order to gauge the current state of LLMs in the domain of financial services, we surveyed a broad range of models, including:
GPT-4-Turbo (GPT-4)
GPT-3.5-Turbo (GPT-3.5)
Zephyr-7b-beta (Zephyr-7b)
Llama-2–7b-chat-hf (Llama-2–7b)
Llama-2–70b-chat-hf (Llama-2–70b)
Mistral-7B-Instruct-v0.2 (Mistral-7b)
Mixtral-8x7B-Instruct-v0.1 (Mixtral)
SOLAR-10.7B-Instruct-v1.0 (SOLAR-10.7b)
For the remainder of this article, we will refer to each of these models by the names shown in parentheses.
Additionally, we attempted to leverage domain specific models like Finance-Chat, but found that its performance was significantly lower than its peers and decided to exclude it from our results.
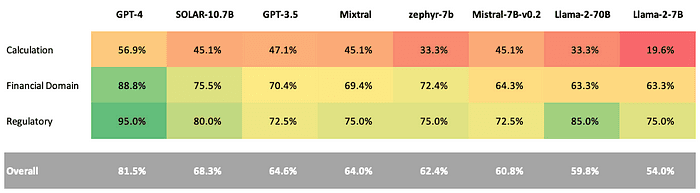
Current LLMs Perform Poorly on Financial Text: The table above reports the overall results on our benchmark across all models that we surveyed. GPT-4 significantly outperforms all other models with an overall accuracy of 81.5% while most other models fall somewhere in the 60–70% range. All models struggle mightily with calculation questions, but even within the other buckets of questions, error rates across all models are unacceptable for production use cases within the financial sector. This suggests the need for financial institutions to adopt more sophisticated systems built on top of LLMs which are able to pull-in domain knowledge and perform high-fidelity calculations (likely through code generation/execution) when necessary.
Open-Source Models have Eclipsed GPT-3.5: SOLAR-10.7b is the best open-source LLM for financial text, showing a significant performance improvement over GPT-3.5 (68.3% avg. accuracy vs. 64.6%), particularly when answering questions in the financial domain and regulatory buckets. While there is still a significant gap between open-source models and GPT-4, this indicates that open-source is quickly working to close it. Furthermore, a couple of other open-source models, Mixtral and Zephyr-7b, also perform on par or slightly better than GPT-3.5 excluding the calculation-type questions. We plan on adding new models to our benchmark in the future — if you have any suggestions or requests, please contact us.
GPT-4 is the Best LLM for Financial Text: GPT-4 outperforms the next best LLM by ~13%, dominating each of the three different types of questions. Not only does GPT-4 synthesize financial text better than other models, but we also noticed that it is more capable at providing a suitable answer even when some information may be missing in order to answer the question completely. The table below highlights this behavior in an example where GPT-4 was the only model to correctly answer the question.

GPT-4 correctly states that there is an increase in the amount of various deposits while all other models hallucinate exact numbers for this increase (this information is missing from the context).
Calculation Remains a Major Gap in LLMs: Llama-2–7b performance on calculations was abysmal, registering accuracy of 19.6%. Llama-2–7b and Zephyr-7b both had calculation accuracies of 33.3%. Both Mistral-7b and Mixtral performed exactly the same on calculation questions (45.1%), though Mixtral overall outperformed Mistral-7b by ~3%. Only GPT-4 crossed the 50% accuracy threshold on calculation questions. Calculation is a known pitfall of current-generation LLMs, necessitating the use of computation agents in order to answer these types of questions.
Our benchmark is being leveraged by financial institutions today to evaluate and rank the best LLMs for their use cases. Please reach out to us if you are interested in accessing our benchmark.
Potential Limitations:
GPT-4 as an Evaluator: Several of the models within this benchmark (GPT-4, SOLAR-10.7b, GPT-3.5, and Zephyr-7b) all have some exposure to GPT-4’s preferences, either through Direct Preference Optimization (DPO), or through underlying training data. As a result, there is a possibility that the GPT-4 evaluator may be biased to prefer responses from these models.
In order to understand this potential issue better, we manually analyzed results between pairs of models before and after GPT-4 alignment. Specifically, we examined outputs from SOLAR-10.7b and Zephyr-7b vs. Mistral-7b — both SOLAR-10.7b and Zephyr-7b are results of training a Mistral-7b model on further data curated by GPT-4.
Calculations: We did not observe any evaluator bias, as GPT-4 evaluates all models’ answers correctly in this bucket. The Zephyr-7b model performs significantly worse than Mistral-7b in this bucket (33.3% vs. 45.1%), seemingly suffering from forgetting. On the other hand, SOLAR-10.7b is able to maintain the same level of performance as Mistral-7b, likely due to the fact that its alignment data explicitly includes mathematical questions in it.
Note: Forgetting is a phenomenon whereby a model loses competency on previously learned concepts when exposed to new information
Financial Domain Knowledge: When manually reviewed by domain experts, it appears that models aligned to GPT-4 produce better answers within this bucket of questions, rather than resulting from an insignificant bias to GPT-4’s preferences. Specifically, we find that answers from GPT-4 aligned models tend to show an improved ability to pick up useful information and filter extraneous information. Below is an example of this behavior:

Regulatory Knowledge: Within this question type, it is possible there is some GPT-4 evaluator bias, as we cannot identify a clear reason for the observed improvement in the answers of GPT-4 aligned models. As a future direction, it would be interesting to consider using another model as an evaluator (e.g. Prometheus-13b-v1.0) in order to study how evaluator bias impacts this benchmark.
Dataset Creation
Our research involved assessing the quality of several LLMs on question-answering tasks from 10-K and 10-Q documents — key financial statements that companies submit quarterly to the SEC and the public. The process of creating our benchmark dataset contained two steps 1) creating informative golden contexts, and 2) generating questions grounded in these golden contexts.
Creating Gold Contexts
The baseline for our golden contexts is this 10-K dataset hosted on Hugging Face. Each sample within it provides an individual sentence from 10-K documents spanning 4,677 different companies — an example is shown below:
We recognized pretax closure costs of $4.3 million in the fourth quarter primarily related to severance costs and asset impairment charges.
In order to ensure our golden context had sufficient information to generate a relevant question and were not too scattered in the concepts it contained, we grouped consecutive samples into paragraphs of around 10 sentences. We then randomly selected 3 groupings across 66 different companies to ensure diverse representation across the different sections of 10-K documents as well as companies. Finally, we manually filtered samples where the context did not contain substantive information. Our final dataset represents 189 total samples across the 66 companies. An example of a golden context from our benchmark dataset is shown below:
Higher base salary expense and commission expense drove the increase. The increase in base salaries primarily reflected merit raises and the increase in commissions was related to the residential mortgage and retail securities brokerage businesses. Occupancy. Occupancy expense (including premises and equipment) totaled $22.7 million for 2020, $18.4 million for 2019, and $18.5 million for 2018. For 2020, the $4.3 million, or 23.4%, increase in consolidated occupancy expense reflected the addition of $2.8 million in occupancy expense from CCHL. Core CCBG occupancy expense increased $1.5 million primarily due to higher FF&E depreciation and maintenance agreement expense (related to technology investment and upgrades), maintenance for premises, and pandemic related cleaning/supply costs. Pandemic related costs reflected in occupancy expense for 2020 at Core CCBG totaled approximately $0.3 million and will phase out over a period of time as the pandemic subsides. For 2019, the $0.1 million, or 0.4%, decrease from 2018 generally reflected the closing of two offices in 2019. Other. Other noninterest expense totaled $31.0 million in 2020, $28.8 million in 2019, and $29.1 million in 2018.
Generating Questions Grounded in Gold Context
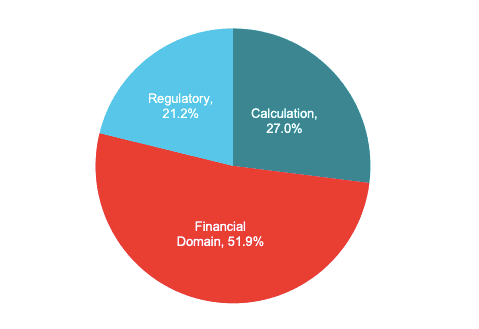
Provided the constructed golden contexts, we used GPT-4 to generate questions based on the critical information contained in the context. During generation, we prompted the model to generate questions from three different buckets of questions, whichever was most relevant given the provided golden context. The three buckets we chose are calculations, financial domain knowledge, and regulatory knowledge as these represent the vast majority of questions that bankers or lawyers may specifically refer to a 10-K document to answer. Our benchmark’s distribution across these three buckets can be seen in the figure below, and we provide more details on each bucket following it.
Calculations: Relates to metrics, growth rates or other simple calculations using information from 10-K documents (and often from the three major financial statements or relevant addendums) and asks for potential context around the trend.
Example:
What was the total cost of share repurchases in fiscal 2020, and why might the Company’s share repurchase cost have decreased from fiscal 2019 to 2020?
Financial domain knowledge: Relates to broader financial and accounting concepts (like inventory, growth rates, multiples) and often asks for a comparison of the given business’ characteristics in relation to what might be expected of the broader industry.
Example:
How do the company’s billing practices affect the recognition of accounts receivable and deferred revenue, and how does this align with the typical financial reporting standards?
Regulatory knowledge: Relates to rules, laws or regulations and requires deep understanding of how companies may adhere to them or mitigate chances of litigation in their operations and disclosures.
Example:
What regulatory provisions ensure that Virginia Power and DESC separately conduct wholesale power sales operations from nonregulated plants, and how do these rules prevent competitive advantage for nonregulated entities?
Evaluation
Each LLM was provided the golden context and question for each sample in our generated dataset, and then prompted to answer the question. We specifically chose to include this golden context in order to evaluate LLMs’ abilities to understand and synthesize financial language without confounding performance gaps with retrieval issues. In order to evaluate the correctness of an LLM’s response, we leverage GPT-4 as an evaluator to validate if a response is correct or incorrect. 20% of all evaluations were manually screened to ensure that GPT-4 provided adequate results.
Conclusion
Our research highlights the challenges faced by AI in understanding and answering financial and legal questions — areas that require high precision and comprehensive knowledge.
While the top performers showcased promising results, the experiment demonstrates that even with the ideal “golden” context, all of these models need significant adaptation to be applicable and reliable in most use cases.
As a part of Farsight’s commitment to push the boundaries of AI and its applications in the enterprise, we’re working on solutions that can further enhance model performance on a wide array of tasks — including financial analysis. Stay tuned for more insights on this topic in our upcoming posts.
For any questions or additional information on our research or Farsight more generally, please feel free to contact us.
An LLM Benchmark for Financial Document Question Answering
Jan 24, 2024
Generative Artificial Intelligence (GenAI) has unlocked a multitude of new applications across numerous sectors, including financial services. As part of our continuous efforts to explore the potentials and limitations of AI, we at Farsight conducted an experiment to evaluate the capabilities of various popular Large Language Models (LLMs) in the context of financial document analysis, particularly 10-Ks and 10-Qs — a quarterly report filed by public companies regarding their financials.
Our results include three major findings:
Out-of-the-box LLMs have far from satisfactory performance: Even when provided the necessary context to answer a financial question, out-of-the-box LLMs spectacularly fail to meet the production standards required in the financial sector, with most models incorrectly answering ~40% of questions.
Rising strength of open-source: While GPT-4 remains the top model, GPT-3.5’s performance has been eclipsed by the open-source SOLAR-10.7b model.
Calculation tasks remain a major pitfall: 7 of the 8 models evaluated failed on over half of calculation-related tasks they were presented with. GPT-4 led all models with only 57% accuracy on such tasks.
We constructed our benchmark from a 10-K dataset hosted on Hugging Face. Based on contexts drawn from this dataset, we generated questions covering 3 categories of interest (calculations, financial domain knowledge, and regulatory knowledge) using GPT-4-Turbo. We then ask a variety of LLMs to answer these questions given the relevant context, and finally, evaluate each model’s responses using GPT-4-Turbo to determine correctness based on the information provided in the associated context. Unlike existing financial benchmarks, we emphasized design decisions that enable automation and extensibility throughout this process in order to facilitate repurposing this work for benchmarking LLMs in other domains, as well as other specific financial services use cases.
Our main objectives of this benchmark were to:
Understand the outright performance of current-generation LLMs on financial text, given golden context. We explicitly include golden context so performance gaps are not confounded with retrieval errors.
Compare performance between LLMs (open-source and closed-source) across three types of questions (calculations, financial domain knowledge and regulatory knowledge).
Present an efficient and automated method to evaluate various foundation models on domain-specific tasks (our process is 100x more efficient than current practices for evaluation).
Note: Golden context refers to a small snippet of content (2–3 paragraphs) that contains a substantial portion of the information needed to correctly answer a question.
We provide our results and analysis first, then elaborate further on our dataset creation and evaluation process.
Results + Analysis
In order to gauge the current state of LLMs in the domain of financial services, we surveyed a broad range of models, including:
GPT-4-Turbo (GPT-4)
GPT-3.5-Turbo (GPT-3.5)
Zephyr-7b-beta (Zephyr-7b)
Llama-2–7b-chat-hf (Llama-2–7b)
Llama-2–70b-chat-hf (Llama-2–70b)
Mistral-7B-Instruct-v0.2 (Mistral-7b)
Mixtral-8x7B-Instruct-v0.1 (Mixtral)
SOLAR-10.7B-Instruct-v1.0 (SOLAR-10.7b)
For the remainder of this article, we will refer to each of these models by the names shown in parentheses.
Additionally, we attempted to leverage domain specific models like Finance-Chat, but found that its performance was significantly lower than its peers and decided to exclude it from our results.
Current LLMs Perform Poorly on Financial Text: The table above reports the overall results on our benchmark across all models that we surveyed. GPT-4 significantly outperforms all other models with an overall accuracy of 81.5% while most other models fall somewhere in the 60–70% range. All models struggle mightily with calculation questions, but even within the other buckets of questions, error rates across all models are unacceptable for production use cases within the financial sector. This suggests the need for financial institutions to adopt more sophisticated systems built on top of LLMs which are able to pull-in domain knowledge and perform high-fidelity calculations (likely through code generation/execution) when necessary.
Open-Source Models have Eclipsed GPT-3.5: SOLAR-10.7b is the best open-source LLM for financial text, showing a significant performance improvement over GPT-3.5 (68.3% avg. accuracy vs. 64.6%), particularly when answering questions in the financial domain and regulatory buckets. While there is still a significant gap between open-source models and GPT-4, this indicates that open-source is quickly working to close it. Furthermore, a couple of other open-source models, Mixtral and Zephyr-7b, also perform on par or slightly better than GPT-3.5 excluding the calculation-type questions. We plan on adding new models to our benchmark in the future — if you have any suggestions or requests, please contact us.
GPT-4 is the Best LLM for Financial Text: GPT-4 outperforms the next best LLM by ~13%, dominating each of the three different types of questions. Not only does GPT-4 synthesize financial text better than other models, but we also noticed that it is more capable at providing a suitable answer even when some information may be missing in order to answer the question completely. The table below highlights this behavior in an example where GPT-4 was the only model to correctly answer the question.
GPT-4 correctly states that there is an increase in the amount of various deposits while all other models hallucinate exact numbers for this increase (this information is missing from the context).
Calculation Remains a Major Gap in LLMs: Llama-2–7b performance on calculations was abysmal, registering accuracy of 19.6%. Llama-2–7b and Zephyr-7b both had calculation accuracies of 33.3%. Both Mistral-7b and Mixtral performed exactly the same on calculation questions (45.1%), though Mixtral overall outperformed Mistral-7b by ~3%. Only GPT-4 crossed the 50% accuracy threshold on calculation questions. Calculation is a known pitfall of current-generation LLMs, necessitating the use of computation agents in order to answer these types of questions.
Our benchmark is being leveraged by financial institutions today to evaluate and rank the best LLMs for their use cases. Please reach out to us if you are interested in accessing our benchmark.
Potential Limitations:
GPT-4 as an Evaluator: Several of the models within this benchmark (GPT-4, SOLAR-10.7b, GPT-3.5, and Zephyr-7b) all have some exposure to GPT-4’s preferences, either through Direct Preference Optimization (DPO), or through underlying training data. As a result, there is a possibility that the GPT-4 evaluator may be biased to prefer responses from these models.
In order to understand this potential issue better, we manually analyzed results between pairs of models before and after GPT-4 alignment. Specifically, we examined outputs from SOLAR-10.7b and Zephyr-7b vs. Mistral-7b — both SOLAR-10.7b and Zephyr-7b are results of training a Mistral-7b model on further data curated by GPT-4.
Calculations: We did not observe any evaluator bias, as GPT-4 evaluates all models’ answers correctly in this bucket. The Zephyr-7b model performs significantly worse than Mistral-7b in this bucket (33.3% vs. 45.1%), seemingly suffering from forgetting. On the other hand, SOLAR-10.7b is able to maintain the same level of performance as Mistral-7b, likely due to the fact that its alignment data explicitly includes mathematical questions in it.
Note: Forgetting is a phenomenon whereby a model loses competency on previously learned concepts when exposed to new information
Financial Domain Knowledge: When manually reviewed by domain experts, it appears that models aligned to GPT-4 produce better answers within this bucket of questions, rather than resulting from an insignificant bias to GPT-4’s preferences. Specifically, we find that answers from GPT-4 aligned models tend to show an improved ability to pick up useful information and filter extraneous information. Below is an example of this behavior:
Regulatory Knowledge: Within this question type, it is possible there is some GPT-4 evaluator bias, as we cannot identify a clear reason for the observed improvement in the answers of GPT-4 aligned models. As a future direction, it would be interesting to consider using another model as an evaluator (e.g. Prometheus-13b-v1.0) in order to study how evaluator bias impacts this benchmark.
Dataset Creation
Our research involved assessing the quality of several LLMs on question-answering tasks from 10-K and 10-Q documents — key financial statements that companies submit quarterly to the SEC and the public. The process of creating our benchmark dataset contained two steps 1) creating informative golden contexts, and 2) generating questions grounded in these golden contexts.
Creating Gold Contexts
The baseline for our golden contexts is this 10-K dataset hosted on Hugging Face. Each sample within it provides an individual sentence from 10-K documents spanning 4,677 different companies — an example is shown below:
We recognized pretax closure costs of $4.3 million in the fourth quarter primarily related to severance costs and asset impairment charges.
In order to ensure our golden context had sufficient information to generate a relevant question and were not too scattered in the concepts it contained, we grouped consecutive samples into paragraphs of around 10 sentences. We then randomly selected 3 groupings across 66 different companies to ensure diverse representation across the different sections of 10-K documents as well as companies. Finally, we manually filtered samples where the context did not contain substantive information. Our final dataset represents 189 total samples across the 66 companies. An example of a golden context from our benchmark dataset is shown below:
Higher base salary expense and commission expense drove the increase. The increase in base salaries primarily reflected merit raises and the increase in commissions was related to the residential mortgage and retail securities brokerage businesses. Occupancy. Occupancy expense (including premises and equipment) totaled $22.7 million for 2020, $18.4 million for 2019, and $18.5 million for 2018. For 2020, the $4.3 million, or 23.4%, increase in consolidated occupancy expense reflected the addition of $2.8 million in occupancy expense from CCHL. Core CCBG occupancy expense increased $1.5 million primarily due to higher FF&E depreciation and maintenance agreement expense (related to technology investment and upgrades), maintenance for premises, and pandemic related cleaning/supply costs. Pandemic related costs reflected in occupancy expense for 2020 at Core CCBG totaled approximately $0.3 million and will phase out over a period of time as the pandemic subsides. For 2019, the $0.1 million, or 0.4%, decrease from 2018 generally reflected the closing of two offices in 2019. Other. Other noninterest expense totaled $31.0 million in 2020, $28.8 million in 2019, and $29.1 million in 2018.
Generating Questions Grounded in Gold Context
Provided the constructed golden contexts, we used GPT-4 to generate questions based on the critical information contained in the context. During generation, we prompted the model to generate questions from three different buckets of questions, whichever was most relevant given the provided golden context. The three buckets we chose are calculations, financial domain knowledge, and regulatory knowledge as these represent the vast majority of questions that bankers or lawyers may specifically refer to a 10-K document to answer. Our benchmark’s distribution across these three buckets can be seen in the figure below, and we provide more details on each bucket following it.
Calculations: Relates to metrics, growth rates or other simple calculations using information from 10-K documents (and often from the three major financial statements or relevant addendums) and asks for potential context around the trend.
Example:
What was the total cost of share repurchases in fiscal 2020, and why might the Company’s share repurchase cost have decreased from fiscal 2019 to 2020?
Financial domain knowledge: Relates to broader financial and accounting concepts (like inventory, growth rates, multiples) and often asks for a comparison of the given business’ characteristics in relation to what might be expected of the broader industry.
Example:
How do the company’s billing practices affect the recognition of accounts receivable and deferred revenue, and how does this align with the typical financial reporting standards?
Regulatory knowledge: Relates to rules, laws or regulations and requires deep understanding of how companies may adhere to them or mitigate chances of litigation in their operations and disclosures.
Example:
What regulatory provisions ensure that Virginia Power and DESC separately conduct wholesale power sales operations from nonregulated plants, and how do these rules prevent competitive advantage for nonregulated entities?
Evaluation
Each LLM was provided the golden context and question for each sample in our generated dataset, and then prompted to answer the question. We specifically chose to include this golden context in order to evaluate LLMs’ abilities to understand and synthesize financial language without confounding performance gaps with retrieval issues. In order to evaluate the correctness of an LLM’s response, we leverage GPT-4 as an evaluator to validate if a response is correct or incorrect. 20% of all evaluations were manually screened to ensure that GPT-4 provided adequate results.
Conclusion
Our research highlights the challenges faced by AI in understanding and answering financial and legal questions — areas that require high precision and comprehensive knowledge.
While the top performers showcased promising results, the experiment demonstrates that even with the ideal “golden” context, all of these models need significant adaptation to be applicable and reliable in most use cases.
As a part of Farsight’s commitment to push the boundaries of AI and its applications in the enterprise, we’re working on solutions that can further enhance model performance on a wide array of tasks — including financial analysis. Stay tuned for more insights on this topic in our upcoming posts.
For any questions or additional information on our research or Farsight more generally, please feel free to contact us.

© 2024 Farsight AI, Inc.
All rights reserved.
Corporate HQ:
One Kendall Square, Suite B2102, Cambridge, MA 02139
NY Office:
2 Park Ave (Floor 20), New York, NY 10016
© 2024 Farsight AI, Inc.
All rights reserved.
Corporate HQ:
One Kendall Square, Suite B2102, Cambridge, MA 02139
NY Office:
2 Park Ave (Floor 20), New York, NY 10016
© 2024 Farsight AI, Inc.
All rights reserved.
Corporate HQ:
One Kendall Square, Suite B2102, Cambridge, MA 02139
NY Office:
2 Park Ave (Floor 20), New York, NY 10016